
查询分离定义
每次写数据时保存一份数据到另外的存储系统里,用户查询数据时直接从另外的存储系统里获取数据
什么时候使用
- 数据量大;
- 所有写数据的请求效率尚可;
- 查询数据的请求效率很低;
- 所有的数据任何时候都可能被修改;
- 业务希望我们优化查询数据的功能。
查询分离实现思路
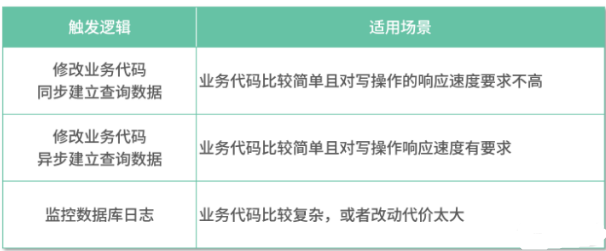
(一)如何触发查询分离?
分为3种
(1) 修改业务代码:在写入常规数据后,同步建立查询数据。
(2) 修改业务代码:在写入常规数据后,异步建立查询数据。
(3) 监控数据库日志:如有数据变更,更新查询数据。
(二)如何实现查询分离?
这里主要讲解第二种
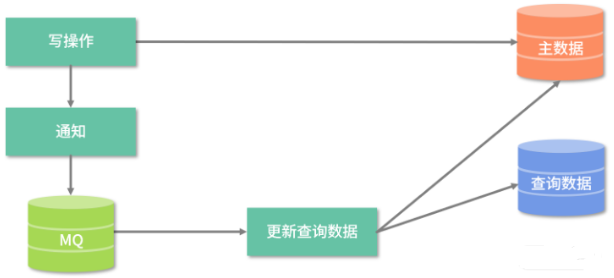
修改业务代码异步建立查询数据,最基本的实现方式是单独起一个线程建立查询数据,不过这种做法会出现如下情况:
- 写操作较多且线程太多,最终撑爆 JVM;
- 建查询数据的线程出错了,如何自动重试
- 多线程并发时,很多并发场景需要解决。
此时使用 MQ 管理这些线程即可解决
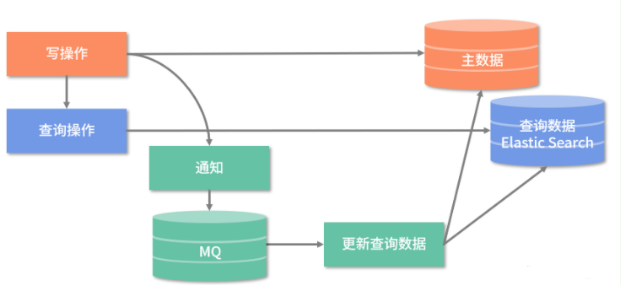
(三)查询数据如何存储?
市面上主要使用 Elasticsearch 实现大数据量的搜索查询,当然还可能会使用到 MongoDB、HBase 这些技术
(四)查询数据如何使用?
因 ES 自带 API,所以使用查询数据时,我们在查询业务代码中直接调用 ES 的 API 就行。
整体方案
有用的话打赏一下?👇